Création d'un projet type : Transcription
Depuis le header, je clique sur Create new project.

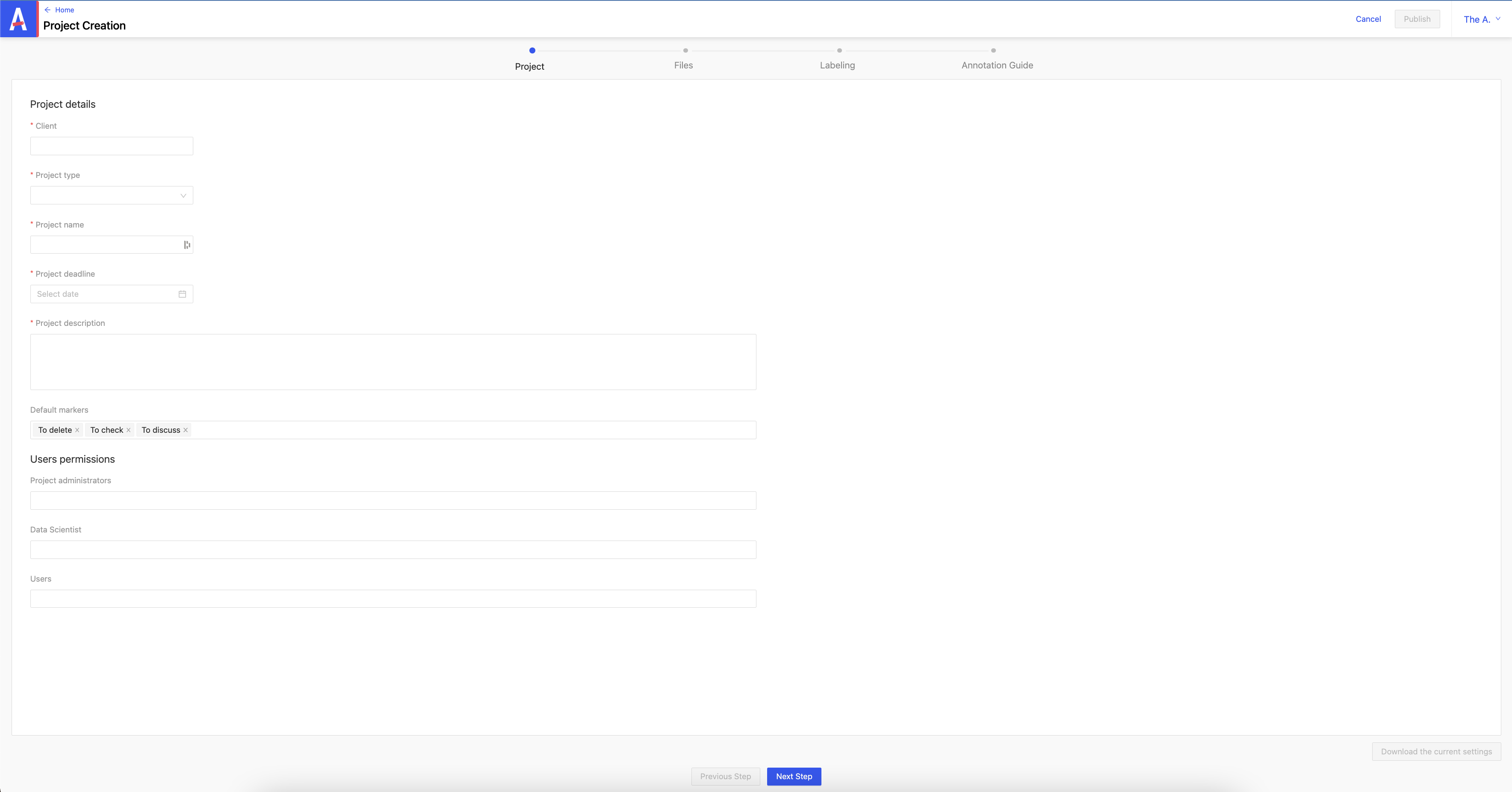
1/ Étape Project
On renseigne les champs obligatoires :
- Client
- Project type
- Project name
- Project deadline
- Project description
Les champs non obligatoires :
- Default markers : apparaît sur l’item plus tard
- to delete : indique un item à supprimer
- to check : indique un item à vérifier
- to discuss: indique un item à discuter
On peut définir des niveaux d’accès à l’item importé à :
- l’admin
- le data scientist
- l’utilisateur
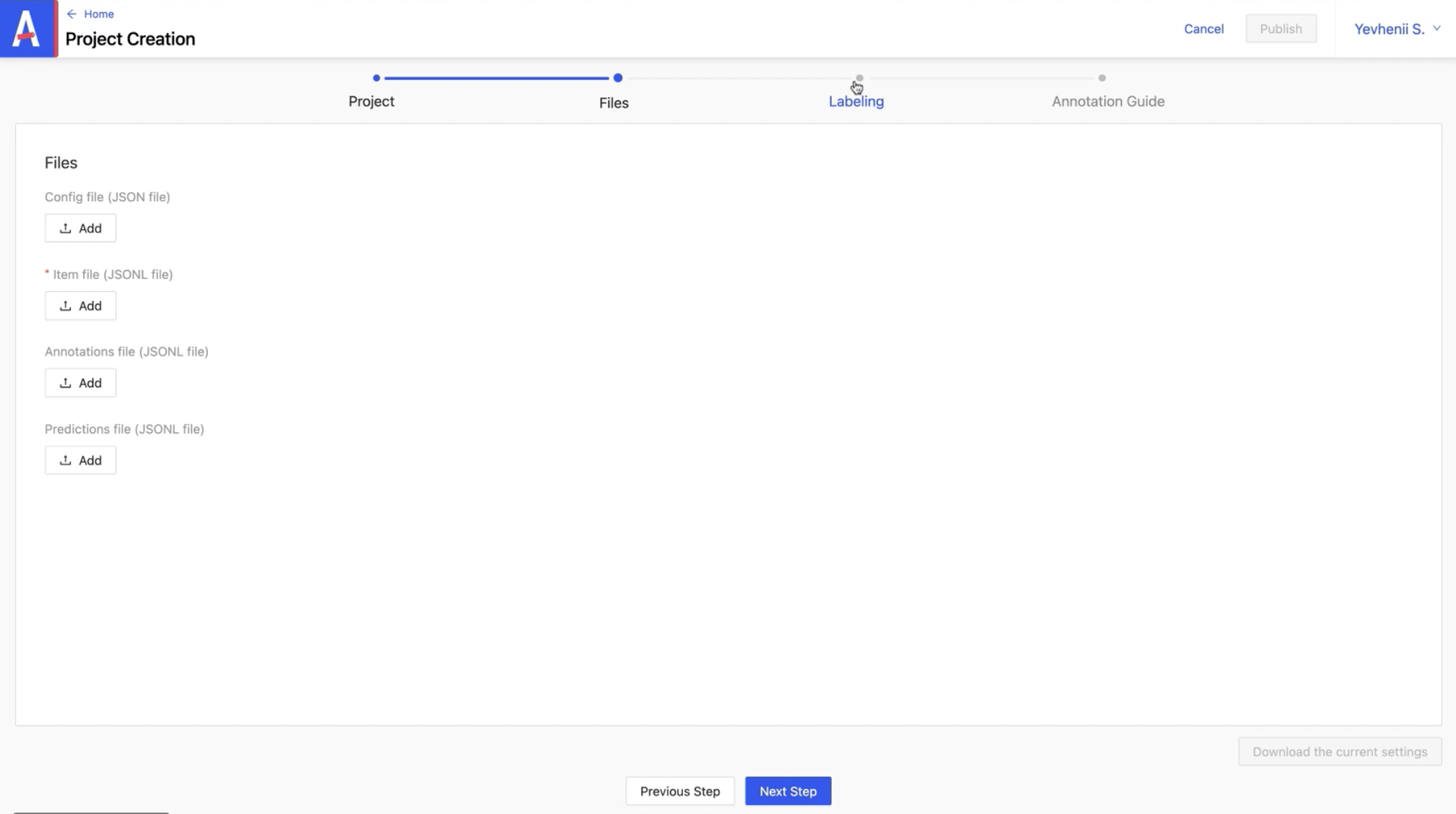
2/ Étape Files
les champs :
- Config file: fichier de config
- Annotations file: fichier contenant les annotations liées à l’item
- Predictions file: fichier contenant les predictions liées à l’item
Contrairement aux annotations, les prédictions viennent d’un modèle pré-entraîné. Après l’import, on pourra choisir de les garder ou non.
Quant au champ obligatoire :
- item file : c’est une liste qu’il faut préparer à l’avance comprenant le type de l’item et une id unique
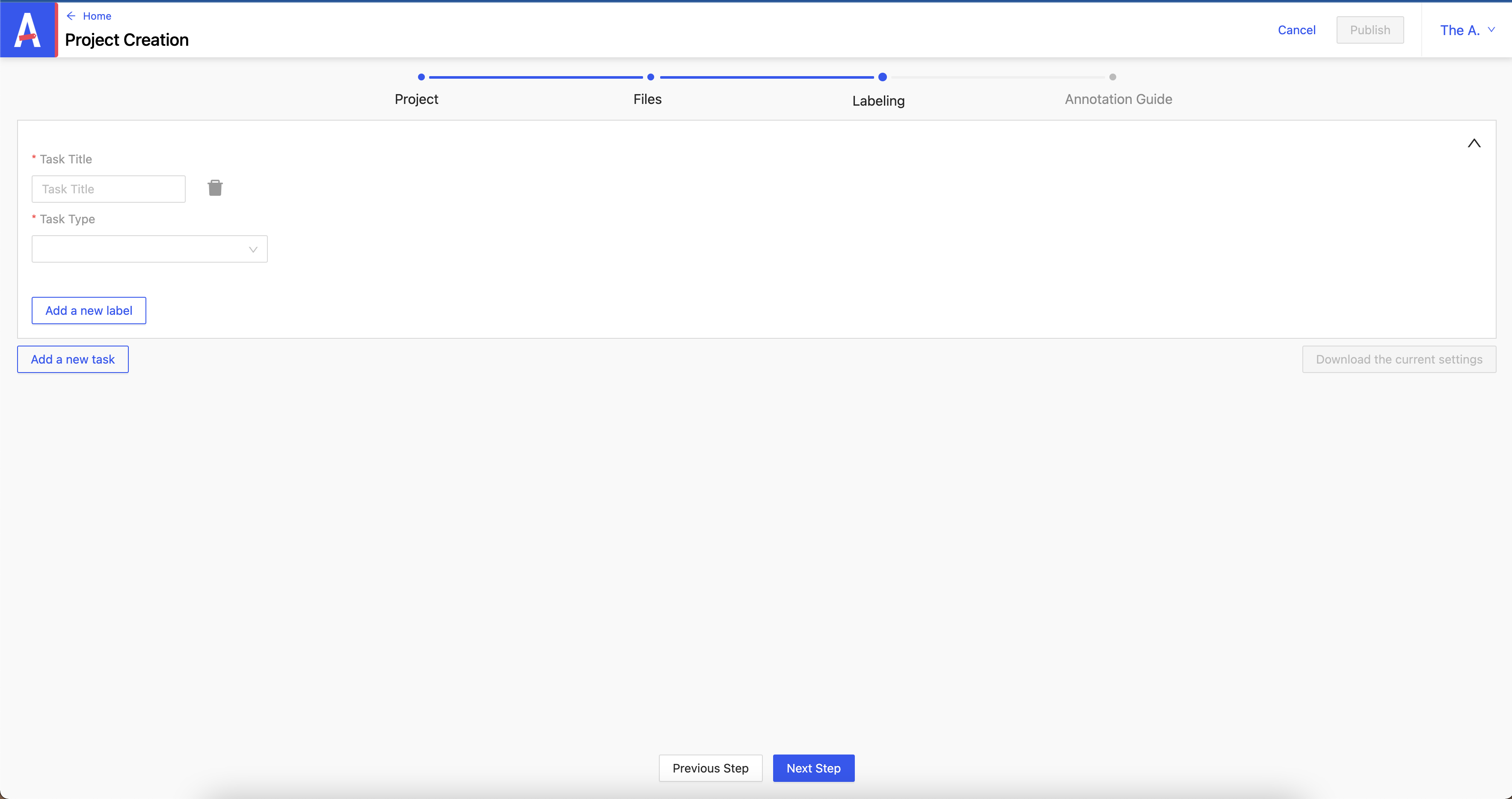
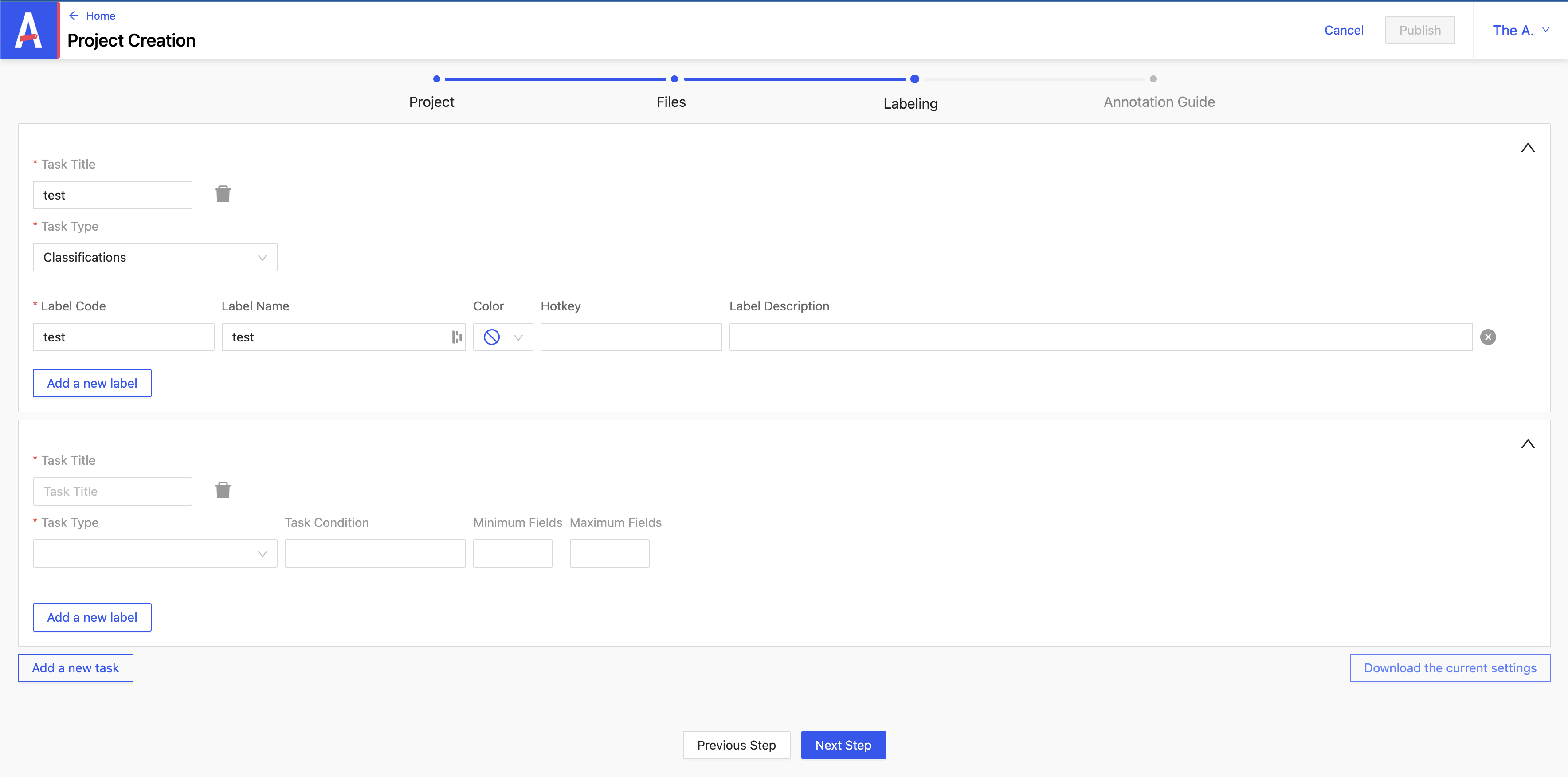
3/ Étape Labeling
On va définir ce qu’on veut faire avec notre projet.
- Task Title : définit le nom
- Task Type : définit le type
On peut ajouter un nouveau label en cliquant sur Add a new label.
Les champs :
- Label Code : doit être unique
- Label Name : ne doit pas forcement porter le même nom que Label Code
- Color : définit la couleur du label
- Hotkey : permet de créer un raccourci clavier
- Label Description : une description du label
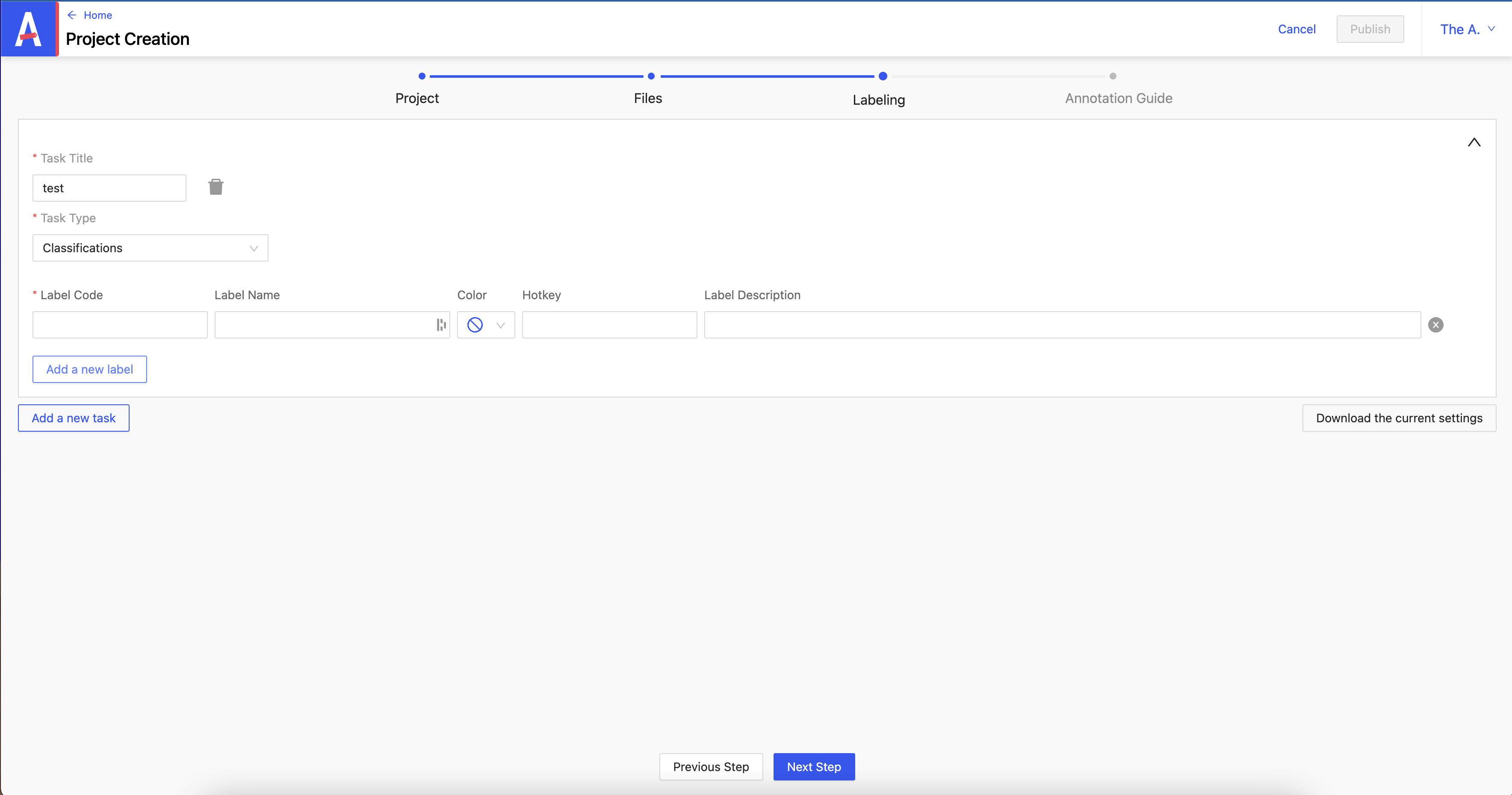
Une fois ces labels définis, il n’est plus possible de les modifiers par la suite.
4/ Étape Annotation Guide
On peut ici définir des règles d’annotations.
Une fois les spécifications d’un projet renseignées, on peut cliquer sur Add a new task pour commencer à renseigner les détails d'un autre projet.
exemple d'un fichier de config
{
{
"text": [
{
"name": "text",
"values": [
{
"parents": [],
"exposed": true,
"type": "text",
"annotationPourcent": 100,
"annotationCount": 3,
"_id": "634837bf795c92001ed8ae54",
"project": "634837bf795c92001ed8ae53",
"value": "text",
"label": "text",
"category": "text",
"updatedAt": "2022-10-13T16:07:27.503Z",
"createdAt": "2022-10-13T16:07:27.503Z",
"__v": 0
}
]
}
],
"name": "DEMO: OCR",
"client": "LJN",
"type": "image",
"highlights": [],
"description": "test text task",
"admins": [
"admin@test.com",
"data@test.com",
],
"users": [],
"dataScientists": [],
"defaultTags": [
"To delete",
"To check",
"To discuss",
"quality",
"empty"
],
"showPredictions": true,
"prefillPredictions": true,
"filterPredictionsMinimum": 0.4,
"deadline": "2022-12-31T10:41:24.456Z",
"entitiesRelationsGroup": []
}
}
exemple d'un fichier d'items
{
{"predictions":{},
"uuid":"ec0a4c92-f5f6-11eb-a271-acde48001122",
"data":{"url":"s3://data-for-demo-ljn/invoice-parsing/data/constat_circumstance/CDN_MAYENNE1_PAPER_20210401104747_00001_001_002_CONSTAT_Page_1_0.jpg"},
"type":"image",
"metadata":{},
"description":"",
"annotated":false,
"createdAt":1665677247548,
"velocity":null,
"lastAnnotator":{},
"seenAt":"2022-10-27T04:00:48.724Z"
}
exemple d'un fichier d'annotation
{
"item": {
"uuid": "ec0a4bb6-f5f6-11eb-a271-acde48001122",
"datatype": "image",
"data": {
"url": "s3://data-for-demo-ljn/invoice-parsing/data/constat_circumstance/CDN_MAYENNE1_PAPER_20200417145911_00001_001_002_CONSTAT_Page_1_0.jpg"
}
},
"itemMetadata": {
"createdAt": 1665677247548,
"updated": "2022-10-27T04:00:17.438Z",
"seenAt": "2022-10-27T04:00:17.437Z"
},
"tags": [],
"comments": [],
"metadata": {},
"annotationMetadata": {
"annotatedBy": "admin@test.com",
"annotatedAt": "2022-10-14T01:46:43.973Z",
"createdAt": "2022-10-14T01:46:43.964Z"
},
"annotation": {
"text": {
"text": {
"entities": [
{
"value": "text",
"text": "17"
}
]
}
}
},
"historicAnnotations": []
}